Data Sharing Patterns as a Tool to Tackle Legal Considerations about Data Reuse with Solid: Theory and Applications in Europe
Dirk De Bot1, Tom Haegemans1,2,*
* Corresponding author
1 Digita, R&D Dept., Breydelstraat 34-40 - 1040 Brussels, Belgium
2 KU Leuven, Department of Decision Sciences and Management Information Systems, Naamsestraat 69 - 3000 Leuven, Belgium
This document is the first version of a ‘living document’. You can find an up-to-date version at go.digita.ai/reuse-patterns.
The corresponding author can be contacted at tom@digita.ai or tom.haegemans@kuleuven.be.
This project has received funding from the European Union’s H2020 research and innovation programme under Grant Agreement no 871498.
Table of content
2. Personal data reuse in a Solid ecosystem and legal difficulties 5
Solid: a personal data web that fosters data privacy and enables data reuse 5
Striking aspects from a legal perspective 5
Application of the current legislation and the importance of context 6
3. Methodology & Limitations 6
Personal Data Reuse Patterns to Tackle Legal Considerations in a Solid Ecosystem 7
Pattern 1: Direct data exchange with consent 7
Pattern 2: Indirect data exchange with provision 8
Pattern 3: Direct data exchange with feedback 9
Practical and Solid Compliant Implementation of the Patterns 10
Component 1: The user instructs to reuse data from a pod. 10
Variation 2: Rely on Data Browser 11
Component 2: The user puts existing data in a pod. 12
Variation 1: Rely on User Initiative 12
Variation 2: Rely on Data Browser 13
Component 3: The user receives information about what data is or was reused for. 13
Variation 1: Information in Privacy Policy 14
Variation 2: Continuous Privacy Feedback 14
Legal considerations to determine which pattern should be followed 14
Consideration 1: Lawfulness of processing by the recipient 15
Consideration 2: Specific and applicable legal framework 16
Consideration 3: Consent as part of the legal framework 17
Consideration 4: Compatibility of purpose 17
Consideration 5: Free consent 18
Consideration 6: Free provision 19
The considerations in context 19
B2G - Business to Government 21
G2G - Government to Government 21
G2B - Government to Business 22
5. Application to selected use cases 23
Case 1: Sharing payslips to determine whether people are entitled to a social contribution 23
Case 2: Receiving updates of Belgium’s national registry 23
1. Introduction
Recently, much attention has been given to Tim Berners-Lee’s Solid specification. This is not surprising as the Solid specification is meant to let people easily reuse their data from one party at another party and will thus lead to many positive advancements. To start, people have more control over and transparency of the data organisations store about them. Furthermore, due to data reuse, people can experience better and more seamless digital journeys. And, in addition, organisations can onboard customers more easily using their digital channels - especially in those journeys when the customer traditionally needed to provide a lot of information manually.
There are a few reasons why Solid enables better data reuse and, in effect, leads to several positive consequences. A first reason is because the specification requires both semantic and syntactic interoperability between the systems on which this data is stored. A second reason is that the Solid specification is, in fact, a set of rules that combines several tried and tested web technologies and concepts (e.g. uniform resource identifiers, URIs) that have proven to be capable of structuring a massive information system such as the world wide web.
Even though many of those concepts are not new, their application to personal data in organisations is. And, this novelty leads to many unclarities regarding regulation and technical implementations. For example, current legislation like the GDPR is not tailored to the situation that, in the Solid ecosystem, a person can reuse his/her personal data that is currently stored at an organisation (say A) with another organisation (say B) by providing a URI to a set of data values stored at organisation A to organisation B and instructing organisation A to provide continuous (i.e. online) access to organisation B.
Fortunately, we noticed that many scenarios in which the legislation and technical implementations are unclear, can be tackled with a relatively limited set of patterns. And, those patterns are also particularly suited to describe several legal and technical considerations.
As such, the goal of this study is to first identify data sharing patterns as tools to tackle legal considerations in a solid environment and describe how these patterns can be technically implemented in a way that is compliant with the Solid specification. Next, to explain which (legal) considerations should be taken into account per context. Finally, to demonstrate the practical value and the applicability of the results by applying them to a diverse set of real-life cases.
The remainder of this report is structured as follows. Section 2 explains several aspects of data reuse in a Solid ecosystem and explains why it is not straightforward to apply the current legislation to those aspects. Section 3 describes how this research distills the data reuse patterns and other results. Section 4 delineates the results. Section 5 applies the results to a set of selected use cases. Section 6 and 7 discuss and conclude the research.
2. Personal data reuse[1] in a Solid ecosystem and legal difficulties
Solid: a personal data web that fosters data privacy and enables data reuse
Solid is a set of (open) technical rules that should enable ethical storage and transfer of personal data. The specification, which will soon be an open W3C standard, gives rise to a personal data web in which each individual can access one or multiple pods containing his or her personal data and use applications, like a personal data browser virtually to combine his or her personal data that reside within those pods. Data browsers are a particularly interesting kind of application within the Solid ecosystem because they can be used by people as an interface to access their data, to see what happened to their data and to give consent to share their data with third parties. As such, data browsers give their owners more control over their data, increase data transparency and enable data reuse.
In this paper, data reuse is considered as the reuse of personal data. In this context, data reuse is often mentioned together with two related but distinct concepts: data access control and consent. Data access control is related in the sense that, when data is reused at a third party, this third party is allowed to access the data. This access is controlled by the party at which the data is stored. Consent is related because when personal data is reused at another party, it may be necessary (but not always) to get a consent of the data subject.
Striking aspects from a legal perspective
There are several aspects of data reuse in a Solid ecosystem that give rise to additional questions when it comes to data protection legislation and technical implementation.
A first striking aspect is that Solid enables continuous data sharing (i.e. online) on top of the traditional way of sharing a copy of the data (i.e. offline). That is, when a person decides to reuse his/her data from one party at another in a Solid ecosystem, it is possible to grant the receiving party direct and continuous access to his/her data that is stored at the originating party. This works because in Solid, access to data can be granted by using URIs and access control lists.
A second striking aspect is that Solid enables to retain the authenticity of data when it is reused by a person. When the recipient has online access to the data, it is possible to rely on the trustworthiness of the source at which the data is stored. If the recipient has offline access or receives the data indirectly, the authenticity can be retained by digitally signing the data.
A third striking aspect is that data reuse in Solid might involve more parties and involve those parties in a different way than how data is traditionally reused. For example, in a Solid ecosystem, the person that wishes to reuse data, could simply instruct the party at which an original copy of the data is stored to grant the recipient of the data continuous (i.e. online) access to this original copy.
Application of the current legislation and the importance of context
The first two aspects are relatively straightforward to explain with the current legislation. That is, according to the current legislation, the GDPR, it does not matter whether data is reused by an offline or online connection or whether the authenticity is retained[2].
The third aspect, however, cannot be answered in a straightforward way. The reason for this is because the answer depends not only on the context in which data is reused, but also on the jurisdiction in which the data reuse takes place.
Therefore, in this study, we aim to explain which legal considerations are relevant in which context by making use of patterns that make abstraction of frequently occurring scenarios. Because this research is sponsored by a European grant, we scope the results to this jurisdiction and in case there are specifics that are governed by the member states, we take Belgium as an example.
3. Methodology & Limitations
In this research, we adopted the same methodology as in Haegemans et al., 2016 and used grounded theory to analyse observations we made during several exploratory case studies. Exploratory case studies are studies in which data is collected before research questions are formulated (Yin 2014, p. 238) and are thus particularly suited to construct a theory in combination with grounded theory (Yin 2012, p. 29; Eisenhardt 1989; Fernandez 2004).
As grounded theory is a method to induce theory based on empirical findings rather than deduce from existing theory (Eisenhardt 1989, p. 534), the results cannot be considered exhaustive or theoretically complete.
The cases on which the study is based, are presented in Section 5 of this report. Because the cases served as input for the research, they should not be interpreted as a way of validating the research results, but rather as a means to demonstrate the results’ practical applicability.
4. Results
In this section, first, we first introduce the patterns and example Solid implementations, and explain the pattern language on which they are based. Next, we identify several considerations that should be taken into account when deciding which pattern can be implemented. Finally, we describe which considerations are relevant in which context using the concept of decision tables.
Personal Data Reuse Patterns to Tackle Legal Considerations in a Solid Ecosystem
In this section, we introduce three fundamental patterns and explain their specifics. Each pattern can manifest itself in multiple forms. The form that should eventually be implemented in a specific scenario depends on several technical constraints and business requirements[3].
Pattern Modeling Language
Before we can describe the patterns in a visual model, we first need to introduce a language that captures all aspects that are relevant to discuss their legal implications. Table 1 contains the description of the pattern modeling language.
The pattern modeling language and, therefore, the patterns as well are only applicable to one data attribute. This means that when multiple attributes are involved, one should take into account that multiple models are required.
Construct | Name and explanation |
Data flow Indicates that there is a flow of data from the left side to the right side. | |
Control flow Indicates that there flows a message from the left side to the right side. | |
Legal entity Depicts a legal entity. | |
Data subject Depicts a data subject. |




Table 1: A pattern modeling language.
Pattern 1: Direct data exchange with consent
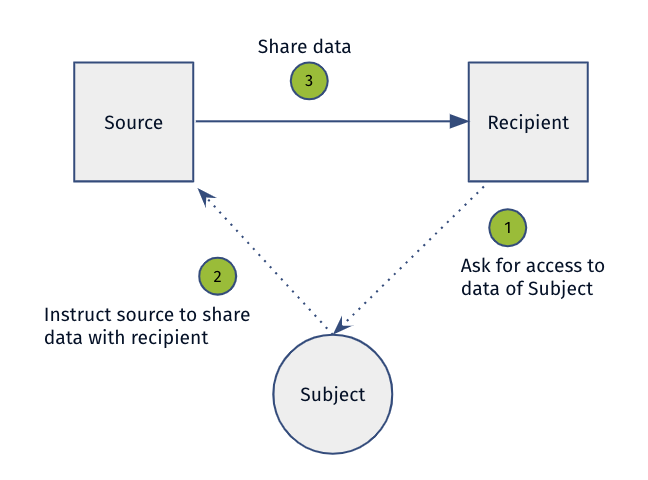
Figure 1: The Direct Data Exchange with Consent (DC) Pattern.
Figure 1 shows the Direct Data Exchange with Consent (DC) Pattern which concerns a direct exchange of data between the source and the recipient. First, the recipient asks the data subject whether it may access his/her data. Then, the data subject instructs the source of the data to share with the recipient. Finally, the source shares the data with the recipient.
The DC pattern is defined by two characteristics. The first characteristic is that the data is directly exchanged between the source and the recipient. The second characteristic is that the subject consents to the data exchange.
This pattern is manifested, for example, in the user journey shown in Figure 2. In this example, a financial institution allows a self-employed person to re-use his/her tax information (which is stored at the government) to easily calculate the optimal amount to put in his/her pension fund.
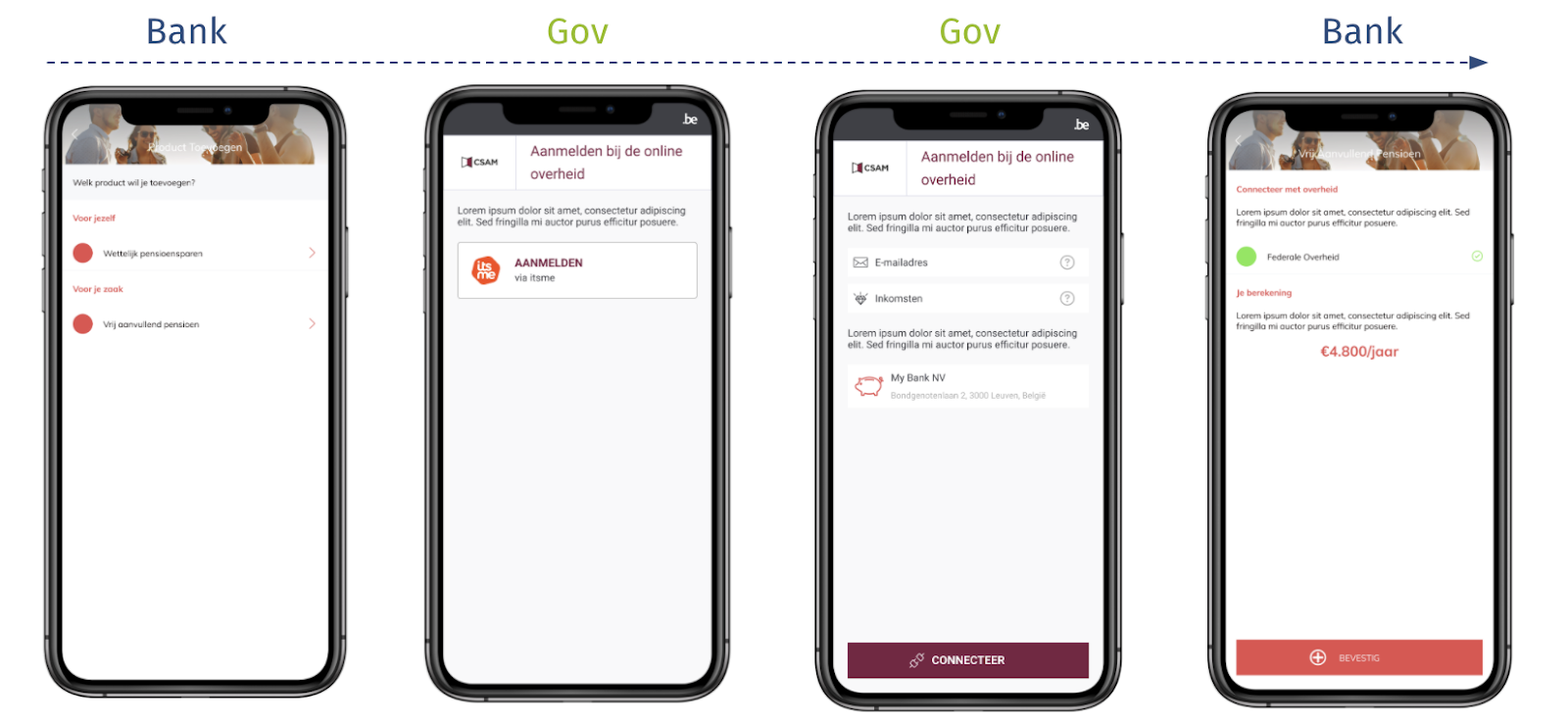
Figure 2: An example implementation of the Direct Data Exchange with Consent (DC) Pattern.
Pattern 2: Indirect data exchange with provision
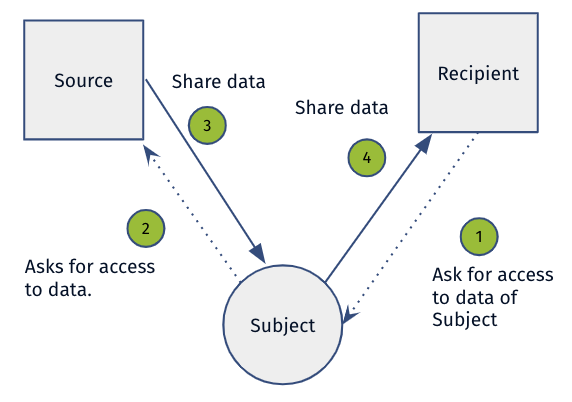
Figure 3: The Indirect Data Exchange with Provision (IP) Pattern
Figure 3 shows the The Indirect Data Exchange with Provision (IP) Pattern which concerns an indirect exchange of data between the source and the recipient. First, the recipient asks the data subject to provision a certain set of data. Then, the data subject asks the source of the data to share his/her[4] data with him/her. Finally, the source shares the data with the data subject who then decides to share his/her data with the recipient.
The IP pattern is defined by two characteristics. The first characteristic is that the data is indirectly exchanged between the source and the recipient. The second characteristic is that the subject explicitly provides the data in the data exchange.
This pattern is widely manifested in multiple contexts. One example is when a person applies for a home loan at a bank. In this case, the bank will probably ask for several payslips of the person to investigate whether s/he is able to repay the loan. Here, the bank (recipient) will first ask the applicant (subject) for his/her payslips (data), next, the applicant will ask his/her employer to provide this data to him/her and, finally, the applicant will pass those payslips back to the bank.
Pattern 3: Direct data exchange with feedback
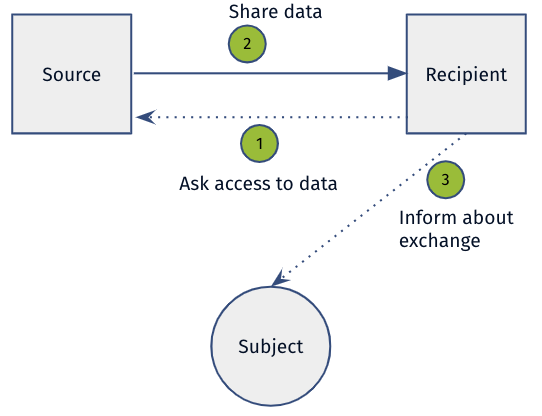
Figure 4: The Direct Data Exchange with Feedback (DF) Pattern.
Figure 4 shows the Direct Data Exchange with Feedback (DF) Pattern which concerns a direct exchange of data between the source and the recipient. However, in contrast to the two previous patterns, in this pattern the subject is not actively involved. The pattern describes the following situation. First, the recipient asks the source to share personal data. Then, the source provides personal data to the recipient and, finally, the data subject receives feedback (is informed) about this exchange.
The DF pattern is defined by two characteristics. The first characteristic is that the data is directly exchanged between the source and the recipient. The second characteristic is that the subject does not explicitly provide the data in the data exchange nor gives a clear consent. The data subject is only informed about the exchange.
This pattern often occurs in the context of data exchange between government agencies for purposes of public interest. For example, in Belgium, when the government needs to send you a form that reports the taxes you paid in the previous year, the government agency that is responsible for collecting taxes (recipient) will first ask the ministry of interior affairs (source) where you live. Next, the ministry of interior affairs shall provide your data to the recipient. After this data exchange, the data subject will receive feedback about this data exchange through his/her personal e-gov dashboard[5].
Practical and Solid Compliant Implementation of the Patterns
When the patterns are implemented in a Solid ecosystem, they give rise to a set of possible user journeys. Regardless of how the exact user journey looks like, three components lie at their basis. Those three components can each be implemented in a variety of ways and are, together with their variations, described in the next paragraphs. Table 2 explains how the components are composed to form the user journeys of the patterns.
Pattern | User Journey |
Pattern 1 | Step 1: Component 1 Step 2: Component 3 The user receives information about what data is or was reused for |
Pattern 2 | Step 1: Component 2 Step 2: Component 1 The user instructs to reuse data from a pod. Step 3: Component 3 The user receives information about what data is or was reused for |
Pattern 3 | Step 1: Component 3 The user receives information about what data is or was reused for. |
Table 2: How the user journeys of the patterns are composed of several components.
Component 1: The user instructs to reuse data from a pod.
This component describes how the user can instruct to reuse his or her data that is controlled[6] by him or her. The data can be stored in a pod that is stored on storage that is managed by an organisation or on storage that is managed by the person himself/herself. The component plays a part in both Pattern 1 and Pattern 2.
We have identified two (non-exhaustive) variations in which this component can be implemented, each with their own benefits and drawbacks (see Table y).
Variation for Component 1 | Benefits/drawbacks |
Rely on User | Benefits
Drawbacks
|
Rely on Data Browser | Benefits
Drawbacks
|
Table 3: The benefits and drawbacks of the variations for Component 1
Variation 1: Rely on User
In this variation, the recipient of the data first shows the user to a screen where s/he is asked to provide data for a specific purpose. Next, if the user agrees, s/he is shown a screen on which s/he can select a provider of where the pod containing the data is stored. After that, s/he needs to authenticate at the pod provider and finally, the data is shared and the user is shown a success message. Figure a shows an example implementation of this variation.
Figure 5: A user journey that is the implementation of Variation 1.
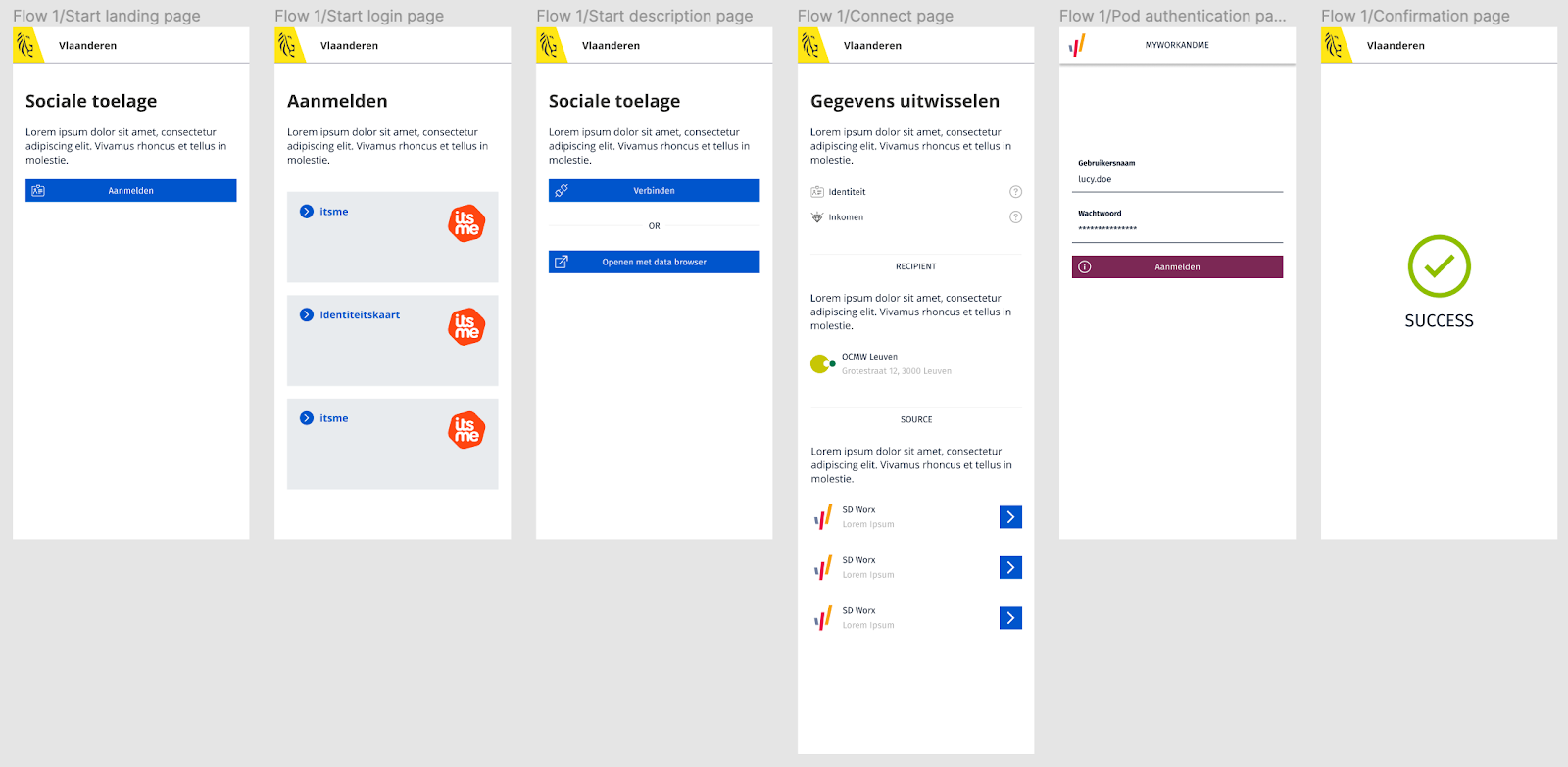
This journey has several drawbacks: the user does not only have to select a pod provider that will serve as the source, but will also have to authenticate at that pod provider. When people will have more than one pod, it will not be easy to keep track of which kind of data will be stored in which pod.
Variation 2: Rely on Data Browser
In this variation, the recipient of the data first shows the user to a screen where s/he is asked to provide data for a specific purpose. Next, if the user agrees, s/he is redirected to his/her pod browser. If the user has already connected his/her pods to his/her pod browser before, the pod browser knows where which information is stored and can provide it to the recipient. When the data is shared, the user is shown a success message[7]. Figure b shows an example implementation of this variation.
Figure 6: A user journey that utilises a data browser to improve the user experience.
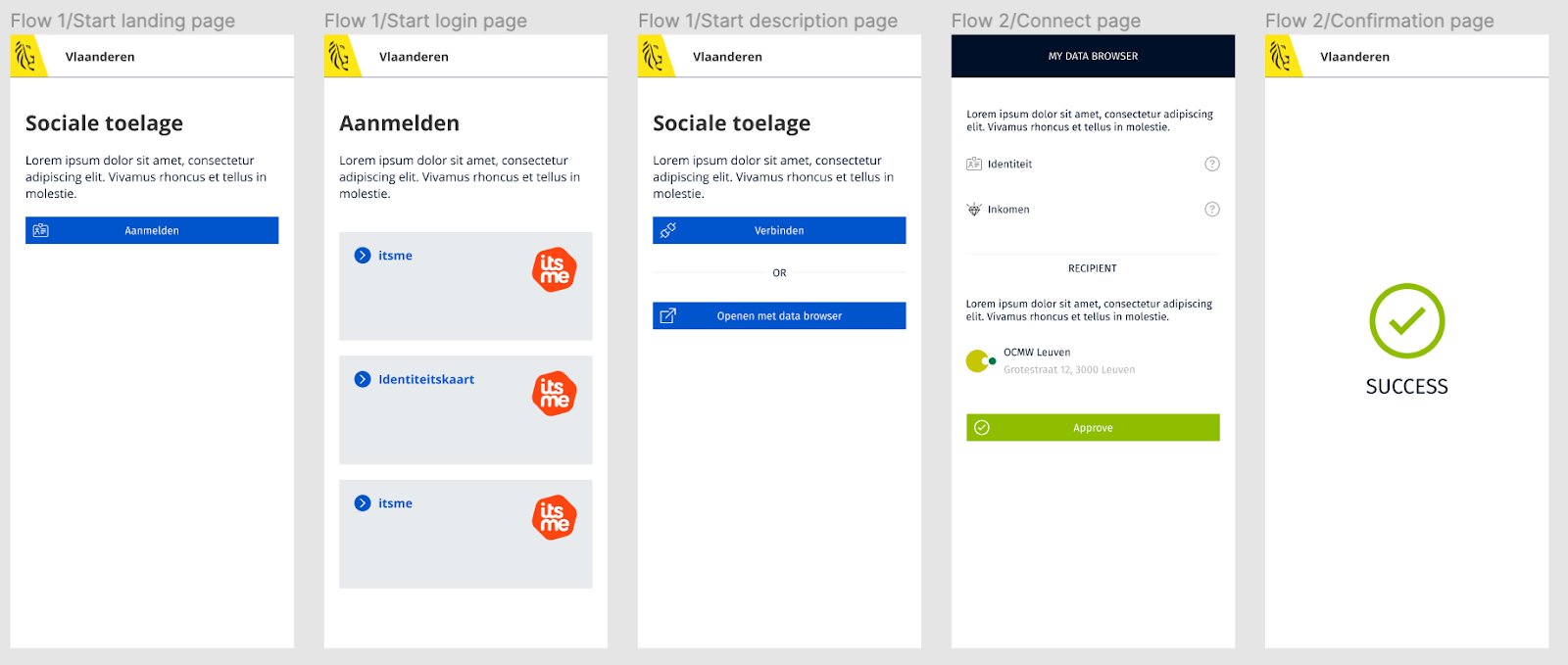
Just like the first variation, this variation also has several drawbacks. That is, first, the concept of a pod browser is relatively new and thus unknown to the general public. Second, the user must have already connected the pods in which the data is stored in the past.
Component 2: The user puts existing data in a pod.
This component is an essential first part of Pattern 2. In this component, the user needs to ensure the data from a third party is stored in a pod so s/he can later reuse this data at other organisations.
Variation for Component 2 | Benefits/drawbacks |
Rely on User Initiative | Benefits
Drawbacks
|
Rely on Data Browser | Benefits
Drawbacks
|
Table 4: The benefits and drawbacks of the variations for Component 2
Variation 1: Rely on User Initiative
One variation to this component is when the user can synchronise his/her data from his/her profile page at an organisation with a pod at an independent pod provider. An example of this variation is shown in Figure 7. Here, the user needs to explicitly synchronise the information with another pod. Which pod the information needs to be synchronised with, should be determined before.
Figure 7: A mock-up of a user interface to demonstrate Variation 1.
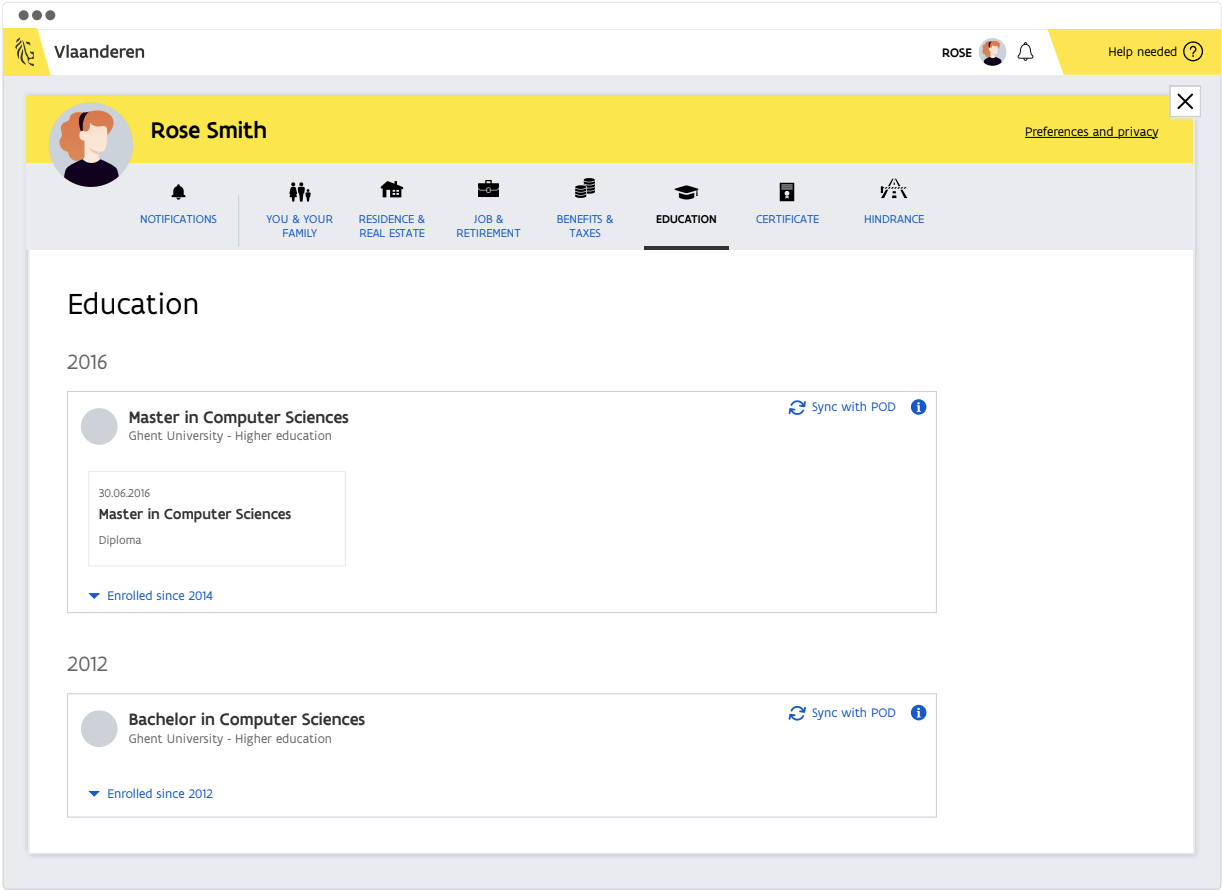
There are at least three important drawbacks of this variation that would hinder the adoption of a Solid ecosystem. First, the user needs to take action to put his/her data in a pod, meaning that everyone should know the concepts behind Solid and what a pod may be used for. Second, there needs to be an independent pod provider at which the data can be stored (currently there is no such party). Third, once the information is transferred from the source to the pod provider, the pod contains a snapshot rather than the up-to-date information.
Variation 2: Rely on Data Browser
The problem of the flow in Variation 1 is that the user needs to undertake action at the source before his/her data can be shared with the recipient. In other words, the user needs to take action proactively. Fortunately, there is another way to achieve the same result without requiring the user to take action at the source in a proactive way. That is, one could use an application at the recipient, specifically for onboarding, that copies the data from the source to the data subject in an ad-hoc fashion. Yet, despite the improved user experience, the pod still contains a snapshot rather than the up-to-date information.
Component 3: The user receives information about what data is or was reused for.
This component is mandatory in all patterns. There are at least two (non-exhaustive) variations of how this component can actually be implemented (see Table 5).
Variation for Component 3 | Benefits/drawbacks |
Privacy Policy | Benefits
Drawbacks
|
Continuous Feedback | Benefits
Drawbacks
|
Table 5: The benefits and drawbacks of the variations for Component 3
Variation 1: Information in Privacy Policy
One way to give a user information on why his or her data was used, is to describe these purposes in a privacy policy and to publish this privacy policy somewhere it is accessible by those users (e.g. on the organisations’ public website). This variation is currently widely adopted.
Variation 2: Continuous Privacy Feedback
In addition to bundling information about why data was used in a privacy policy, organisations can also give such feedback by logging for each person, each purpose for which their data was used (e.g. the purpose of determining whether the person has children). By doing so, the organisation can present these purposes to the person so s/he can report uses that s/he feels was inappropriate.
Figure 8: A bank shows continuous privacy feedback to its customers (i.e. how their data was used).

Legal considerations to determine which pattern should be followed
In this section, we discuss several legal considerations to determine which of the patterns in the previous section should be followed. First, we give a general overview of the considerations. Next, we explain that their order depends on the context in which they are applied, and, we provide, for each context, a decision table of the relevant considerations to determine which of the patterns should be implemented.
Consideration 1: Lawfulness of processing by the recipient
We assume that data is always made available so that the recipient can process the data of the subject. This data processing, and thus also the disclosing of data, must have a sound legal basis. When the data processing has a legal basis, the processing is said to be legitimate or lawful.
Article 6 (1) GDPR provides an exhaustive list of possible legal bases for a processing of personal data: consent, the performance of a contract, compliance with a legal obligation, the vital interests of the data subject, the performance of a task carried out in the public interest and the legitimate interests pursued by the controller.
This consideration depends on the context in which the data is exchanged. The legal bases for processing in the public sector are often different from those in the private sector. Most often, the processing by a government is based on the tasks of general interest that this government performs. When a private organisation processes the data, the basis will rather be found in the performance of a contractual relationship, the exercise of a legitimate interest or consent.
In summary, this consideration leads to the following question: “Is the processing by the recipient lawful?”. In case the answer is yes, the processing by the recipient is lawful. In case the answer is no, the processing by the recipient is not lawful[8].
For example, if the regulations stipulate that data cannot be used for marketing, it is not lawful to process that data for marketing purposes.
Consideration 2: Specific and applicable legal framework
Another consideration is whether or not there is a specific and applicable[9] legal framework[10]. This consideration should only be taken into account when the source of the data exchange is a government (i.e. public organisation), regardless of the recipient[11].
That is, in data protection law, special attention is paid to the provision of data by one government to another government (also called inter-governmental data traffic). This kind or data exchange is subject to special conditions by the legislator, which implies that the mere application of the principles of general data protection law is not sufficient, but that additional conditions are imposed.
In Belgium, these additional conditions depend on the governmental sector in which the data exchange happens. For example, in the social security and health care sectors, a deliberation of the Information Security Committee is required while in other cases, the source and recipient must conclude a protocol. As far as the provision of data from the National Register is concerned, a decision by the competent minister is required. This decision, deliberation and/or protocol are variants of the requirement that the disclosure of data from a public source must be authorised (in one way or another). It is then that it must also be checked whether the conditions of data protection law have been met.
Most often, these specific legal frameworks are applicable to data exchanges between governments where the recipients want to process data for a task in the public interest. As such, these specific and applicable legal frameworks do not require the data subject to consent to the data exchange or take any other initiative[12]. However, even if consent is not required, the data subject must be informed about the data exchange.
In summary, this consideration leads to the following question: “Is there a specific and applicable framework that governs making the data available?”. The answer on this question dictates an outcome which depends on other considerations which are explained in the next sections.
Consideration 3: Consent as part of the legal framework
This consideration is an addition to the previous consideration as it recognises that specific legal frameworks can also include the notion of consent.
However, this consideration will most likely only occur very sporadically. This is because, in the public sector, data can only be exceptionally processed on the basis of the consent of the data subject. This is because the law assumes that the citizen is in a relationship of dependence on the government that prevents him or her from giving free consent to processing and thus making available his or her data.
An example is the possibility for citizens to give their consent to the exchange of a limited number of their data (name, address and death or absence) in the National Registry to private organisations with whom they have a contractual relation.
In summary, this consideration leads to the following question: “Does the specific and applicable framework allow the data subject to consent to making his/her data available?”. The answer on this question dictates an outcome which depends on other considerations which are explained in the next sections.
Consideration 4: Compatibility of purpose
When data is processed, it is always for a specific purpose. The same applies to the exchange or making available of data. When data is exchanged, the data can be processed by the recipient for a different purpose than the one for which it was originally collected and processed by the source.
When data is made available for the same purpose as that for which the source originally collected it, there is not necessarily a problem. Then that purpose is inherent to the original purpose and as such compatible.
When data is made available for another purpose than the one for which the source originally collected it, it must be ascertained whether the other purpose is compatible with the original purpose. If this is the case, there is no immediate problem and the data can be made available. Compatibility[13] indicates that the other purpose is inherent in the original purpose. If that other purpose is incompatible, then communication or making available is not permitted in principle, unless prescribed by the legislator or permission has been obtained for this.
In summary, this consideration leads to the following question: “Is the purpose for which data is made available compatible with the original purpose of data collection?”. If the answer is yes, the legal basis of the collection continues to apply to the communication. Or still, the other purpose of the further processing is part of the original purpose and as such is “covered” by the original legal basis. If the answer is no, the purpose is incompatible. However, incompatibility does not mean that further processing cannot be allowed. The GDPR allows data to be further processed for an incompatible purpose, provided that the data subject consents to this or a member state law permits this.
Consideration 5: Free consent
In case the data is being exchanged directly between the source and the recipient, the exchange often involves the consent of the data subject. When the exchange is based upon consent, this consent must meet the conditions of the GDPR. This means that there must be a "freely given, specific, informed and unambiguous indication of the data subject’s wishes by which he or she, by a statement or by a clear affirmative action, signifies agreement to the processing of personal data relating to him or her".
Consent as a legal concept must be distinguished from a factual consent that takes the form of an instruction. This is particularly the case with regard to the exchange of personal data. While consent is used to indicate that the direct exchange (communication) of data by the source to the recipient has a legal basis, it is also possible to give an instruction to the custodian of the data subject’s Solid pod to transfer or communicate the data to the recipient. This instruction is to be qualified as a mandate to the custodian that executes the decision of the data subject to freely provide the data to the recipient.
The data subject can give consent to the source, recipient, or a third party that manages the data subject’s Solid pod.
- If the data subject gives consent to the source, it means that the source obtains consent to make the data available to the recipient.
- If the consent is given to the recipient, it means that the recipient may request the data directly from the source. The recipient will need to demonstrate the consent to the source.
- If consent is given to the custodian of the data subject’s Solid pod, this is not a consent in the legal sense, but rather an instruction. In practice it means that the data may be made available to the recipient (by the custodian, acting upon instruction of the data subject) and, where appropriate, may be requested in advance.
In all of the above cases, it is essential that the source has sufficient certainty about the consent, i.e. about its legal validity and its object. The responsibility for this ultimately falls to the source that provides access to data or to the custodian of the Solid pod.
In addition, the accountability of the source holder must be taken into account. This means that regardless of who is given the consent, the source holder must be able to record this consent in some way in order to demonstrate it, where appropriate.
When the source of the data is a government, the consent is, in principle, only eligible if the disclosure is not compatible with the purpose of the original collection .
In summary, this consideration leads to the following question: “Can the subject freely consent to his/her data being made available to the recipient?”. If the answer is yes, then, in general, Pattern 1 can be applied. If the answer is no, then one must look at the next consideration that is relevant for a specific context.
Consideration 6: Free provision
In case the data is being exchanged indirectly between the source and the recipient, the exchange is not based on the consent on the data subject, but is based on what we describe as “data provision”. Data provision is when the data subject takes the initiative to provide the data directly to the recipient.
The provision of data by the data subject to the data recipient must be voluntary, which means that there may be no pressure or deception on the part of the recipient. The same reasoning applies to consent where the converse is penalised. As such, in Belgium, the use against a person of fact, violence, threats, gifts and promises is criminalised if it is intended to force a person to give his or her consent to the processing of the personal data concerning him or her (article 227, 3 ° Data Protection Act).
In this context, it is not so much about consent to processing, but about the requirement that data must always be provided freely .
In order to guarantee that the provision is (sufficiently) free, it is advisable to include a provision in the general Member State legislation that the person who makes use of facts, violence, threats, gifts or promises to him or her to force him or her to provide the data that the data subject has obtained by exercising the right of access and/or portability, must be penalised.
In summary, this consideration leads to the following question: “Can the subject freely provide his/her data to the recipient?”. If the answer is yes, then, in general, Pattern 2 can be applied. If the answer is no and this consideration is actually the last one to consider, then, the data may not be exchanged.
The considerations in context
The order in which the considerations should be applied and which considerations are relevant, depend on the context in which the data exchange happens and is summarised in Table 6. Indeed, some considerations are additions to other considerations (e.g. Consideration 2 and 3) while other considerations, such as Considerations 2 and 3, are only relevant when the source of the data is a government.
The reason why the order depends on the context is because different data protection rules apply in the public sector compared to the private sector. For example, in the public sector, data is often processed on the legal basis of “public interest” while in the private sector data is mostly processed on “consent” or “legitimate interest” as legal bases.
Based upon these insights, we make a distinction between the following contexts where the source and the recipient take the form of a business (i.e. a private organisation) or a government (i.e. a public organisation):
- B2B - Business to Business
- B2G - Business to Government
- G2G - Government to Government
- G2B - Government to Business
Order in context | |||||
Consideration | B2B | B2G | G2G | G2B | |
1 | Lawfulness of processing | 1 | 1 | 1 | 1 |
2 | Specific and applicable legal framework | N/A[14] | N/A | 2 | 2 |
3 | Consent as part of the legal framework | N/A | N/A | N/A | 3 |
4 | Compatibility of purpose | 2 | 2 | 3 | N/A |
5 | Free consent | 3 | 3 | 4 | N/A |
6 | Free provision | 4 | 4 | 5 | 4 |
Table 6: The order in which the considerations should be applied.
B2B - Business to Business
In this context, one must first take Consideration 1 into account and ask him/herself whether the processing by the recipient is lawful. Next, one should look at the compatibility of the purpose for which the data is processed by the source and the recipient (Consideration 4). After that, whether the subject can freely consent to his/her data being made available (Consideration 5) and, finally, one can take into account whether the subject can freely provide his/her data to the recipient (Consideration 6).
Table 6 shows the decision table which should be applied when both the source and the recipient of the data exchange are businesses. This decision table exhibits how the questions that correspond to the relevant considerations in a B2B context give rise to a specific outcome.
A decision table should be read from top to bottom and the answer to a question determines how one should proceed. If a cell contains a dash, then the question is not relevant. When all questions are answered, one can see what the output is. For example, in Table 6, suppose one answers Question 1 with “no”, then the output is “Not possible”. If one answers Question 1 with “yes”, then one should take into account Question 2 as well. If the answer to Question 2 is “no”, then one should take into account Question 3 and so on.
Input | ||||||
1 | Is the processing by the recipient lawful? | Yes | Yes | Yes | Yes | No |
2 | Is the purpose for which data is made available compatible with the original purpose of data collection? | No | No | No | Yes | - |
3 | Can the subject freely consent to his/her data being made available to the recipient? | No | No | Yes | - | - |
4 | Can the subject freely provide his/her data to the recipient? | No | Yes | - | - | - |
Output | ||||||
1 | Not possible | x | x | |||
2 | Pattern 1 | x | ||||
3 | Pattern 2 | x | ||||
4 | Pattern 3 | x | ||||
Table 7: The decision table to determine the outcome in a B2B context.
B2G - Business to Government
This context is very similar to the B2B context. Just like in that context, here, one must first take Consideration 1 into account and ask him/herself whether the processing by the recipient is lawful. Next, one should look at the compatibility of the purpose for which the data is processed by the source and the recipient (Consideration 4). After that, whether the subject can freely consent to his/her data being made available (Consideration 5) and, finally, one can take into account whether the subject can freely provide his/her data to the recipient (Consideration 6).
Input | ||||||
1 | Is the processing by the recipient lawful? | Yes | Yes | Yes | Yes | No |
2 | Is the purpose for which data is made available compatible with the original purpose of data collection? | No | No | No | Yes | - |
3 | Can the subject freely consent to his/her data being made available to the recipient? | No | No | Yes | - | - |
4 | Can the subject freely provide his/her data to the recipient? | No | Yes | - | - | - |
Output | ||||||
1 | Not possible | x | x | |||
2 | Pattern 1 | x | ||||
3 | Pattern 2 | x | ||||
4 | Pattern 3 | x | ||||
Table 8: The decision table to determine the outcome in a B2G context.
Table 8 shows the decision table which should be applied when the source of the data exchange is a business and the recipient is a government. This decision table exhibits how the questions that correspond to the relevant considerations in a B2G context give rise to a specific outcome.
G2G - Government to Government
In a G2G context, one should take other considerations into account because, for governments, there are often more specific rules. In this context, one must first take Consideration 1 into account and ask him/herself whether the processing by the recipient is lawful. Next, one should investigate whether there is a specific and applicable framework that governs making the data available (Consideration 2). Then, one should look at the compatibility of the purpose for which the data is processed by the source and the recipient (Consideration 4). After that, whether the framework allows the data subject to give a consent to make his/her data available (Consideration 3) and, finally, one can take into account whether the subject can freely provide his/her data to the recipient (Consideration 6).
Table 9 shows the decision table which should be applied when both the source and the recipient of the data exchange are governments. This decision table exhibits how the questions that correspond to the relevant considerations in a G2G context give rise to a specific outcome.
Input | |||||||
1 | Is the processing by the recipient lawful? | Yes | Yes | Yes | Yes | Yes | No |
2 | Is there a specific and applicable framework that governs making the data available? | No | No | No | No | Yes | - |
3 | Is the purpose for which data is made available compatible with the original purpose of data collection? | No | No | No | Yes | - | - |
4 | Does the specific and applicable framework allow the data subject to consent to making his/her data available? | Yes | No | No | - | - | - |
5 | Can the subject freely provide his/her data to the recipient? | - | No | Yes | - | - | - |
Output | |||||||
1 | Not possible | x | x | ||||
2 | Pattern 1 | x | |||||
3 | Pattern 2 | x | |||||
4 | Pattern 3 | x | x | ||||
Table 9: The decision table to determine the outcome in a G2G context.
G2B - Government to Business
Just like in a G2G context, one should take other considerations into account in a G2B context because, for governments, there are often more specific rules. In this context, one must first take Consideration 1 into account and ask him/herself whether the processing by the recipient is lawful. Next, one should investigate whether there is a specific and applicable framework that governs making the data available (Consideration 2). After that, whether the framework allows the data subject to give a consent to make his/her data available (Consideration 3) and, finally, one can take into account whether the subject can freely provide his/her data to the recipient (Consideration 6).
Table 10 shows the decision table which should be applied when the source of the data exchange is a government and the recipient is a business. This decision table exhibits how the questions that correspond to the relevant considerations in a G2B context give rise to a specific outcome.
Input | |||||||
1 | Is the processing by the recipient lawful? | Yes | Yes | Yes | Yes | Yes | No |
2 | Is there a specific and applicable framework that governs making the data available? | No | No | Yes | Yes | Yes | - |
3 | Does the specific and applicable framework allow the data subject to consent to making his/her data available? | - | - | Yes | No | No | - |
4 | Can the subject freely provide his/her data to the recipient? | No | Yes | - | Yes | No | - |
Output | |||||||
1 | Not possible | x | x | x | |||
2 | Pattern 1 | x | |||||
3 | Pattern 2 | x | |||||
4 | Pattern 3 | x | |||||
Table 10: The decision table to determine the outcome in a G2B context.
5. Application to selected use cases
In this section, we apply the findings of Section 4 to a selected set of use cases. The aim of these applications is to demonstrate the applicability of the findings.
Case 1: Sharing payslips to determine whether people are entitled to a social contribution
In Belgium, there exists a social contribution to help families having an income that lies below a certain limit. To be able to receive this social contribution, families need to prove that their income lies below a certain limit. In urgent cases, one of the ways that families can prove that they are entitled to this social contribution is by showing their payslips of the last few months. Payslips are documents that people get from their employer[15] and contain a detailed breakdown of their wage.
When considering the results of Section 4, we see that this case occurs in a B2G context. That is, a family member (i.e. the data subject) can reuse his/her information that is currently stored at his/her employer at the government to easily apply for a social contribution. As such, the decision table in Table 8 can help us to determine which of the patterns should be applied.
First, we consider whether the recipient lawfully processes the data. In this case, the answer is yes because the recipient will use the data for the performance of a task carried out in the public interest. Second, we investigate whether the purposes are compatible. In this case, the purpose for which the data was originally collected by the source (i.e. to inform you about your wage) is not compatible with the purpose of the recipient (i.e. to determine whether you are eligible for a social contribution). Third, we need to check whether the subject can freely consent to his/her data being made available to the recipient. In this case, the answer is yes because the data subject has a real choice. This means that in this case, we can apply Pattern 1 to organise the data reuse.
Case 2: Receiving updates of Belgium’s national registry
In Belgium and under certain conditions, the law foresees[16] that citizens can give organisations access to certain updates (e.g. address, …) of their record at the national registry. This way, Belgian citizens, when something about them has been changed (e.g. they have moved house, …) do not have to manually send updates to each of the organisations that store data about them.
When considering the results of Section 4, we see that this case occurs in a G2B context. That is, a citizen (i.e. the data subject) can reuse his/her information that is currently stored in the national registry at the government to keep his/her data at his/her suppliers up-to-date in case this information changes (e.g. due to moving house). As such, the decision table in Table 10 can help us to determine which of the patterns should be applied.
First, we consider whether the recipient lawfully processes the data. In this case, the answer is yes because it is arranged by a specific law. Second, we need to investigate whether there is a specific and applicable framework that governs making the data available. In this case, the answer is yes: making the data available is governed by a specific law. Third, we need to look at the specific and applicable framework and check whether the data subject needs to provide consent in order to make his or her data available. In this case, the answer is yes. This means that in this case, Pattern 1 can be applied.
6. Discussion
This manuscript presented several data reuse patterns, examples of their technical implementation in Solid in the form of user journeys and a set of decision tables to determine which patterns are legally valid in a certain scenario.
From a user experience perspective, the user journeys should not be considered as an exhaustive way to implement the patterns in a Solid environment. Indeed, there are probably several other ways to implement the patterns.
From a functional point of view, the first two patterns are largely similar, but, we believe that the first pattern is superior to the second one. That is, when Pattern 1 is applied, the authentic data is not unnecessarily duplicated meaning that it is easier for the recipient to access the most up-to-date version. This is why the decision tables in Section 4 favour Pattern 1 over Pattern 2.
From a legal perspective, one should keep the jurisdiction of law in mind. Even in Europe (i.e., the scope of our study), member states have specific legislation in place. In this manuscript, we took Belgian law as a case. Practically, this means that the principles will probably remain the same, but that the implementations can and will probably differ per member state.
Another question that is related to the legal framework and patterns is “where should the consent be stored?”. In case Pattern 1 is followed, the recipient should store information about when and for what the data subject gave permission to use his/her data and the source should keep evidence that the subject allows him/her to share this data with the recipient. In case Pattern 2 is followed, the recipient should store the same information as it would do for Pattern 1, but the source does not (because Pattern 2 is an indirect exchange). For Pattern 3, this question is irrelevant because this pattern does not require user input.
7. Conclusion
The goal of this study was to identify data sharing patterns as tools to tackle legal considerations in a Solid environment and describe how these patterns can be technically implemented in a way that is compliant with the Solid specification.
In response, we identified three patterns, several example implementations and a framework with considerations to determine, per context, which pattern should be applied and how it could look like in practice. In addition, to demonstrate the practical applicability of the results, we applied the patterns and framework to a set of selected real-life use cases.
In future work, we will aim to refine the patterns and framework based on existing theories using, for example, contextual integrity theory (Nissenbaum 2004) combined with modelling languages used for business process and service orchestration.
References
Eisenhardt, K. M. (1989). Building Theories From Case Study Research. Academy of Management Review, 14(4), 532–550.
Fernández, W. D. (2004). The Grounded Theory Method and Case Study Data in IS research: Issues and Design. Information Systems Foundations Workshop: Constructing and Criticising, 1, 43–59.
Nissenbaum, H. (2004). Privacy as Contextual Integrity. Washington Law Review Association, 79(119), 119–158.
Yin, R. K. (2012). Applications of Case Study Research (3rd ed.). SAGE.
Yin, R. K. (2014). Case Study Research - Design and Methods (5th ed.). SAGE.
Digita BV - TOPOS Office Center - Breydelstraat 34-40 - 1040 Brussels |

[1] The concept of “reuse” may not lead to confusion. This concept is better known as the re-use of public sector information where it has evolved to the concept of open data. Open data as a concept is generally understood to denote data in an open format that can be freely used, re-used and shared by anyone for any purpose. Open data policies which encourage the wide availability and re-use of public sector information for private or commercial purposes, with minimal or no legal, technical or financial constraints, and which promote the circulation of information not only for economic operators but primarily for the public, can play an important role in promoting social engagement, and kick-start and promote the development of new services based on novel ways to combine and make use of such information.
However, this does not mean that the regulations regarding the protection of personal data must not be applied. To that effect, artikel 2 (4) of Directive (EU) 2019/1024 of the European Parliament and of the Council of 20 June 2019 on open data and the re-use of public sector information explicitly states that it is without prejudice to Union and national law on the protection of personal data, in particular Regulation (EU) 2016/679 and Directive 2002/58/EC and the corresponding provisions of national law.
In other words, the re-use of personal data always and first has to comply with the regulations on data protection. Therefore, if the concept “reuse” figures in this rapport, it is used in its generic meaning and not as a specific legal term.
[2] From a legal point of view, it is more important to know whether there is access than how that access occurs (online or offline). The form or modality of the access is part of the information security measures that need to be applied. As far as authenticity is concerned, this is not necessarily an aspect of the legal framework regarding exchange. It is a legal topic on its own that can be part of the framework regarding exchange, but this is not required. This allows us in this report to consider authenticity as a non essential part of the framework.
[3] These technical constraints and business requirements are out of scope and will be described in another report.
[4] This pattern does not necessarily require that the data is “owned” by the subject (i.e. my data). This pattern is also valid when data merely “concerns” the data subject (i.e. data about me).
[5] Belgians can access this file through the following link https://www.ibz.rrn.fgov.be/nl/rijksregister/.
[6] Note that we use the term “controlled” and not “owned”. Indeed, much of the personal data in an organisational context will not be owned by the data subject. In this context, oftentimes, the data subject can only control his or her data to a certain extent. That is, when data about someone is stored at organisations, the data subject is not allowed to simply edit this data (otherwise one could, for example, state s/he has an infinite amount on his/her checking account), but only to reuse his/her data somewhere else or to have additional transparency over what happened to his/her data. This is in contrast to the reason (and context) for which Solid was originally invented: to improve personal data management on social media. Personal data on social media (e.g. photos, likes, friends) is owned by the data subject.
[7] In this case, the user can but does not necessarily need to authenticate again at the pod provider because the internet browser of the user can already have cookies that store session information.
[8] The party who is responsible to check whether this condition is met,is different when the data is exchanged directly compared to when it is exchanged indirectly.
As far as the direct exchange of data from a public source is concerned, this investigation can be part of the prior authorization procedure (if there is one). In all other cases of direct exchange, it is essentially up to the source holder to conduct this research. The reason for this is that making available is always a decision by the source holder who must be accountable.
If it concerns an indirect exchange, the situation is somewhat different. Then there is no direct relation with the source, but a relationship between the data subject and the recipient. In that situation it is not always easy for the data subject to perform this check. Transparency, in particular the obligation to provide information, is an important aid here. Furthermore there is a risk that the recipient requests data that are disproportionate or for purposes that are not lawful. Because it is not evident to check this a priori, it is recommended that a legal provision is provided here by Member States that makes such acts punishable or permits them to be sanctioned.
[9] It is not because a specific framework is applicable that it can actually be applied. That is, in Belgium, the case when the source and recipient are unable to draw up a protocol or that the recipient does not belong to the circle of entities entitled to access the data. The Law organising the National Register determines the entities that are eligible for access to the data in the Register. If one is not part of this circle, the scheme cannot be applied.
This means that each source should always consider whether the regime that applies to it restricts the circle of access rights holders. If that is the case, it must be established that the specific scheme cannot be applied.
[10] It will rarely happen that there is no specific framework for data exchange when a public source is involved. In Belgium, Article 20 Data Protection Act subjects every data communication from a federal authority to a protocol, while Article 8 of the eGov Decree stipulates the same for communication by a Flemish agency. The scope of the regulation is very broad in both cases due to the interpretation of the terms “government” and “agency”.
[11] If the specific framework also applies to making data available to private organizations, it applies to both inter- and extra-administrative data traffic. This is the case, for example, for the regulation contained in Article 20 of the Data Protection Act (the regulation of Article 8 of the eGov Decree only applies to public authorities).
[12] We believe that processing (and making data available) in the public sector cannot be based on the consent of the data subject. After all, there is a relationship of dependence between the government and the citizen that does not allow the citizen to actually release his consent.
Moreover, asking for permission could lead to problems in the functioning of the public sector. In principle, the public interest pursued by governments outweighs individual consent. To that extent, the public interest can be regarded as a form of collective or social consent. This is further confirmed by the consideration that tasks of general interest are in principle assigned by law.
[13] Traditionally, the doctrine of the compatible purpose aims to determine whether the purpose pursued by the recipient is compatible with the original purpose in terms of the source. We believe that this skips an important step, in particular the actual communication of the data by the source.
In our approach means the analysis of the purpose on the part of a recipient is limited to the question whether the processing is carried out for a legitimate purpose and is lawful, i.e. has a legal basis. If so, the analysis is completed. It should be noted in this regard that the (subsequent) processing by the recipient always constitutes an indirect collection (in the legal sense), so that the data subject must in principle be informed of this.
In this approach, we make a distinction between the term “further processing”, which refers to making available (as a way of “further processing” by the source that collected the data), and the term “subsequent processing”, which here refers to processing activities following the indirect collection by the recipient. The distinction is important because, in our opinion, compatibility only refers to further processing and not subsequent processing. This does not mean that the subsequent processing has no influence on the compatibility assessment, but that it is not decisive as such.
In our approach, the emphasis is on the question of whether the source can and may make the personal data available to the recipient. The communication to the recipient is a form of processing within the meaning of Article 4 () GDPR, which means, among other things, that it must have a legal basis (and must be lawful).
The problem is how compatibility is assessed. We believe that compatibility does not refer to the other purpose pursued by the recipient, but rather the other purpose associated with the communication (by the source).
If a controller decides to disclose data for a purpose that he or she does not pursue, but which benefits the recipient, it can and may be assumed that there is some form of commercialization of the data. This commercialization poses more risks for the data subject because he or she threatens to lose control over his or her data. This risk is enhanced by the finding that the data are also processed by other parties with which the data subject has no relationship.
[14] N/A stands for Not Applicable and means that the consideration should not be taken into account in the specific context.
[15] In Belgium, employment legislation is very complex and, therefore, there are organisations called ‘social secretariats’ to help other companies to calculate the amount they have to pay their employees. These social secretariats also store payslips. Yet, to avoid complexity, these organisations are not in scope of the use case.
[16] At the time of writing, this system has not yet been technically implemented.